
Those medical institutions, labs and care providers that have moved over to computerized medical records usually are able to send requests, reports and other communications to each other using computer networks. Often, this is done by third party systems that centralize the conversion of the data. These third parties usually also provide the communication infrastructure and the necessary client applications, but it’s a cultural thing, so it varies a bit from country to country. For a number of reasons, I do think the time has passed for these third parties, even though they’ll probably be in business for a while longer. Nothing in medical computing changes very quickly.
How things are
I have personally designed and built part or most of three systems that do communication of medical data over large distances. All of them use a combination of Internet protocols, Internet applications and public key cryptography. One of them connects to a classic EDI message converter at a central point, the other two don’t convert message content at all, but leave that up to the sender of the message.
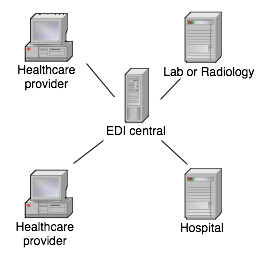
Culturally, and often legally, different countries and regions force certain designs to be used. In Belgium, for instance, the party doing the message routing has to be an independent commercial company (like Medibridge, which I’ve also worked for), to protect the equal access to the system by all parties. That makes sense. In Sweden, regional healthcare providers (“landsting”) can handle their own message exchange since practically all healthcare providers belong to the state anyway. That also makes sense.
In Sweden, a third party can do message conversion, working as “personal data assistant“. Makes sense. In Belgium there is no way a third party would be allowed to open and read medical messages, so the sender and/or receiver has to do the message conversion. Also makes sense.
The problem in Belgium is that each sender has to be able to produce output messages in a format the receiver understands. Having tens of different GP application vendors alone certainly doesn’t help. In reality, the number of message formats for lab reports, for instance, has been reduced by market forces to just a couple. All GP applications can read one or more of these few formats. Each sender has to pay to get his system vendor to install message conversion for these few formats. Well, it works, you know.
In Sweden, third parties generally do the message conversion on a central system, since maintaining conversion scripts or programs on sender’s and receiver’s systems is perceived as unmaintainable. Naturally, this is also a perception vendors of communication systems like to encourage. These third parties also do nothing to standardize the message formats, since that would make their customers less dependent on them.
Why they can’t remain this way
Even though the dominating Swedish communication system uses public key cryptography to the fullest (I know; I designed and built the important parts of it), many regional healthcare managers don’t like having the messages opened by a third party. They also don’t like to have their messages beyond their control, and to have limited influence on how other systems can interface with the system. So, increasingly, they build their own systems instead.
How it should be
Transporting medical messages actually consists of several independent processes:
- Importing and exporting messages from other applications, such as medical records or lab systems
- Converting the message format to the receiver’s message format or an intermediate format, and the conversion from the intermediate format to the receiver’s message format, if necessary
- Applying digital signatures to the sender’s, receiver’s and/or intermediate messages
- Encrypting and decrypting messages
- Routing of messages and message receipts
- Establishment of secure communication channels between nodes in the communicating network
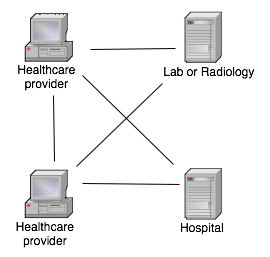
Currently, all of the above functionality is packaged into one indivisible application package by a third party, forcing the customer to buy it all, whatever his needs or desires. The flip side is that it equally forces the customer to reject it all and build everything himself if he needs to, and that is increasingly happening. To me it is obvious that the above functions can and should be packaged as independent products or services.
What needs to be done is to decentralize the system, make it a peer-to-peer architecture with services available to the clients as needed. This would not only increase the robustness of the system, but would allow smaller actors to sell services to the clients, and it would allow the clients flexible paths to expansion of their computing systems. But how do we do that?
Conversion
Writing scripts for message conversion systems is certainly no rocket science, even though the vendors doing medical messaging make it out to be. (While the vendors selling conversion systems make it out to be child’s play.) The only real problem is that these systems are horribly expensive, so very few people are trained on them. Most, if not all, of these systems also only do message conversions on a centrally placed machine, which is not the best way to do this for medical data.
What we need is a small runtime engine that can be run at each healthcare provider site. The price for this engine should be absolutely minimal or even zero. Nothing in my mind says it can’t be any of the many interpreters we can find as open source, such as perl, python or similar.
We also need scripts that can do the required conversions, and a system that stores and selects the correct scripts for a particular conversion. The scripts themselves will be in source form or in obfuscated or encrypted form if they need to be protected as trade secrets. They could also be in semi-compiled form, such as java byte-code or CLI code.
These scripts must be maintainable from a distance. We can’t have people running to and fro with CDs in their hands, installing and updating scripts out in the country. In Sweden, in particular, where there’s a lot of country and not much people, foot-work maintenance is prohibitively expensive. We already update the applications from a distance and without user intervention, so it should not be a problem to do the same with scripts.
Commercially, it could be a good idea to separate out the distribution of the scripts from the construction and maintenance of the scripts. This would allow the customer to create his own scripts for “free” (TANSTAAFL), or have a contractor do it for him. The third party that runs the script distribution system can then charge just for the distribution. Or, alternatively, several independent vendors can distribute scripts in parallel, as long as the application software at the client site is careful to separate the scripts into groups per owner.
Actually, nothing would stop different vendors from maintaining their own scripting engines on the same customer installation. As long as there is a system to route messages to the right scripting engine and script, this should work just fine.
Signatures
Naturally, all kinds of medical documents, be they journal entries, requests or reports, should be digitally signed somehow. Digital signatures present a number of challenges, even once the purely technical obstacles have been overcome.
Semantics
The first problem is “what, exactly, are we signing?”. Most data sent through these systems are heavily dependent on external code sets. For instance, if you order an AIDS test, the actual content of the request may very well be “0101”, which in the destination lab will be translated to “AIDS test” using a code table they have in their system. This is all fine and dandy, but the sender did not sign a request saying “AIDS test”, the sender signed a data structure holding the code “0101”. Without nailing down the relationship to the external table, this is a very dubious thing you’re doing. If the external code table changes at some later point in time, the meaning of the document that was signed also changes without invalidating the signature.
This problem of semantics is very hard to solve, since it carries over to almost every element in the data structure, including the very character set that is chosen to transmit the message. All text is represented as numbers in transmitted data and even though the number “65” means the letter “A” today (in ASCII), it is not guaranteed to be so in a number of years.
Another problem is that if we convert the message to another form that the receiver can understand, any digital signature on the original data does not validate anymore. If we apply the signature only after conversion, on the other hand, the sender can’t actually read the message he is signing, so he’ll be forced to sign blindly, severely reducing the value of the signature in the first place.
A theoretical solution would be to transform all messages to a canonical intermediate form, which is then signed, but even this nifty idea runs into problems. A number of committees have over the years tried to invent such canonical common formats and, so far, always failed to win over the market, so we have no reason to be optimistic about our chances of doing this job successfully in anything like a reasonable timeframe. And even if we could, such a format does not by itself solve the problem of external code tables.
So, what do we do? Throw up our hands in despair and give up? If I answered “yes” here, that would be the end of the article, so I won’t.
What I think we need to do is to separate the human readable document from the machine readable and sign both independently. We can construct a system where the following digital signatures are produced:
- Digital signature on a bitmap
- Digital signature on source data before conversion
- Digital signature on converted data
Digital signature on bitmap
To allow a human to judge what he is actually signing, the application that produces the message in the first place, be it a journal entry, a request or a report, should produce a simple bitmap graphic of the document and allow the user to sign this bitmap. If the bitmap is held very simple and conforming to a standard graphic format that is lossless and can be expected to exist many years hence (such as BMP), there should be no problem for a future expert to unambiguously reproduce the graphic and verify the signature. This signed bitmap need not necessarily accompany the data across the network; the decision to do that is dependent on data security policies, but it does need to be preserved as long as the medical records are preserved. But this is a lawyer thing, so I’ll not discuss this principle further.
What is important is that the application that renders the bitmap on the user’s screen and allows him to sign it, must be secure and guaranteed to be free from malicious code.
Digital signature on source data
Another digital signature is produced by the application on the data structure it delivers to the converter. The validity of this signature is relative to the particular version of the software and reliability of the vendor of the software. How, exactly, the vendor and the software is certified, would need to be nailed down by some kind of committee.
The signature on the data structure is verified by the data conversion software. The conversion software should never process a message without a valid signature from an acceptable source application.
Digital signature on converted data
Finally, the data conversion script and script engine cooperate to sign the converted data before it is passed on to the next stage, which could be transport and/or another data conversion process.
Where do the signatures go?
So, what do we do with these signatures once they have been checked and validated? We could just throw them away, but that seems such a waste. We could leave the signatures in the messages as they go through the different stages, so as the message at long last arrives, it contains a series of digital signatures, most of which the receiver can’t actually verify. But the receiving system can identify the source of the signatures and it can store them as a form of tracking.
Alternatively, all the forms of the message can be included in the message as it goes through the conversions, each new conversion being added to an ever-growing data structure. This allows the receiving system to actually verify all the different signatures, even though it can’t actually understand the messages themselves.
Saving all messages and signatures at the receiver’s end is probably the most comprehensive strategy, but a more modest and almost as useful strategy would be to save the bitmap and its signature plus the final form of the data structure and its signature. The intermediate messages and signatures could be discarded, but again, this is a lawyer thing, so YMMV.
Encryption
Many communication links are encrypted using, for instance, the encryption algorithms available in SSL. This is necessary but not sufficient. Each message must individually be encrypted as well, to be protected during storage and on store-and-forward systems. In what follows, I assume we use public key cryptography (PKC) and that the reader knows how these work. I don’t assume any one particular PKC, such as S/MIME or PGP; they are all suitable for the task, but there are important differences in how the trust relationships are formed and ensured, which I will not cover in this text.
Encryption is often done after signing the document, and that is acceptable in this case as well. In the systems I designed so far, I created detached signatures, that is signatures that are kept outside the encrypted document, which made tracking easier, but it is not an absolute necessity to do things this way. The important thing is that the signature is applied to the plain text document, else it would become meaningless after decryption.
Encryption is always done using the key of the immediate recipient, so the source application encrypts to the conversion system, while the conversion system encrypts with the key belonging to the next destination en route to the ultimate destination. If the conversion system is on the same physical machine and in the same process as the source application, the message may not need to be encrypted at all between these two processes. But if the message is stored in between these applications, I really think it should be encrypted. Your motto should be: you can’t encrypt too much or too often.
Transmission
Transmission between store-and-forward systems, source applications, destination applications and any intermediate converters should be protected by an encrypted communication pipe such as SSL/TLS. This is just another encryption protection, but it also reduces the risks of traffic analysis. Adding client authentication to SSL tunnels is a definite plus, but in no way obviates the need for PKC encryption of the messages or the need for digital signatures. Transmission can also be done using any of a number of other tunneling/VPN techniques, but the take-away here is that the transmission should always be protected in a reliable way.
Conclusion
This blog entry turned out much larger than I intended to, and still, I only scratched the surface of the topic. In summary, what we need to make the medical communication systems of tomorrow is:
- A healthy dose of PKS/PKI systems
- Small, cheap, script engines at end-user systems
- A distribution and management mechanism for the scripts
- An open system of routing and communication
I’ll get back to details on these systems in future blog entries.