
In an interview with Computer Sweden, Dan Egerstad explains that he indeed used Tor exit nodes, five of them. Then he sat back and collected both logon credentials and email contents of all the confused souls who thought that Tor protected them.
The Dan Egerstad affair
Thinking about the Dan Egerstad affair and reading the comments to the Wired article, it may very well be that he set up a Tor node and simply caught credentials when people routed unsecured POP connections through Tor and exited through his node. This makes a lot of sense. I can very well imagine embassy people, and others, using Tor because it’s a great security product, while completely misunderstanding what it’s for.
Maybe that explains why Dan is so cool about getting sued for this. Assume he set up a Tor node for non-malicious reasons, then added a sniffer to it to make sure it wasn’t being used illegally, like for child porn (the sniffer would only give useful info for those sessions that used his Tor node as an exit node, of course). So when he then checks the logs, he finds all these POP email credentials in his own logs on his own machine. He goes on to publish these, not actually using them to get into the email boxes? Has he done anything illegal? I don’t think so. People put their credentials on his machine entirely unasked and of their own volition. They even went to the trouble of installing a Tor client to be able to.
Maybe he did set the whole thing up to catch the credentials, but if he sticks to a very plausible story like the above, there’s no provable intent, is there?
I don’t know for sure this is what happened, but if it didn’t, it will.
Note: in the comment to the above article, “anonymouse” writes that it is an MITM attack using false SSL/TLS certs at the Tor exit node, but that would only be necessary if the victim used SSL protected POP connections through Tor and I don’t see why they would. If they were naive enough to think Tor would do anything at all for their email security, I don’t think they would be savvy enough to add SSL to the POP.
Who stole my signature?
It’s high time we got our signatures back. Since IT systems were introduced in healthcare, handwritten signatures have lost all importance, not because they’re superfluous, but because the IT application vendors can’t get a grip on how to implement them. And the weird thing is that all of us, including the authorities, just let this go on with hardly a notice. In fact, we’ve regressed more than a hundred years as far as this issue is concerned and we’re ok with that?
We need digital signatures in our healthcare applications and we need them badly. As things are now, we sign journal entries and prescriptions with just a mouse-click (or ten mouse-clicks in some apps, you know who you are). If you prescribe heavy analgetics or sedatives you need to prescribe on special numbered forms and add your own personalized sticker (in Sweden), but if it’s electronic you just click. Anyone can do that if they find a way to log in as me. Almost anyone can do that if they can get an SQL command line to the database. How am I to defend myself against allegations that I prescribed something bad or entered a stupid note on a patient if this is how the system works? I can’t!
We trust the application and by implications its developers. The developers trust the OS and the IT department running the app and all this trust is totally misplaced and nothing is verified. The applications regularly misplace notes and change content due to bugs, and still we trust them?
Technically, there’s only one decent solution today and that’s digital signatures based on assymetric crypto systems. It’s not that difficult to implement and we don’t even need a very extensive public key infrastructure (PKI). All we need is the keys and a local certification authority (CA).
The keys have to be created on a USB dongle or a smart card and the private keys should never leave it. The local workstation could do the processing, but once better USB dongles or smart cards are easily available, the processing should be moved to those. That’s all pretty easy since all modern operating system support all this so the applications don’t need to.
It’s also important that the signature is applied to two structures: the machine data and a bitmap of the same data as it would have looked on paper. The machine data by necessity is incomplete and its interpretation dependent on external information and the application intended to process it. For example: it’s entirely possible that a prescription or a lab request contains only codes for the products or tests, while external tables that are not part of the signed data structure contain the corresponding product or test name. That means that I may put my signature on a prescription for the code for aspirin today, but which could turn into a prescription for methadon if combined with another external table, without invalidating my digital signature. If, on the other hand, the accompanying bitmap showed an oldfashioned paper prescription for aspirin, I could use that as (almost) human readable proof of what I actually signed any time in the future.
I think it’s not too much asked that the vendors get their asses moving and get this thing done.
Twisted keyboards
I’m often working as a GP in Sweden. The desktop computers we get are usually bog standard Dells, with all the excitement that goes with that…. not! (Think Borat.) All of them alike: boring but almost adequate. You can sit down at any one of them and start blindly typing away into the electronic patient records without a second thought. The only thing marring the experience is the intermittent but constant swearing at the software, both EHR and Windows, but it’s something that becomes a part of you. I think even the patients are getting used to it.
For some reason, and it has to be sadism, Dell makes two very similar kinds of keyboards where the only noticeable difference is the orientation of the Ins/Del/PgUp/PgDn/Home/End keypad above the arrow keys. The regular orientation is horizontal, that is two rows of three keys, right? Well, the alternative is a sicko three rows of two keys.
The IT department, naturally, has ordered a mix of these two types, just to keep things interesting. So there you are, typing away happily with the cursor skipping to all kinds of places you didn’t intend, until you discover some %#$&$# SOB moved the keys around!
I can understand that some people may want the alternate layout for their machines, but we’re talking about a large number of bog standard machines here, and users moving from one to the next all the time.
How ^%$#$(* idiotic do you have to be to do this to your users?!?
WMWare appliances as a vector
Just saw mention on a forum of downloading a VMWare appliance ready-to-run parental control package. It’s definitely a great convenience to get a pre-installed entire OS with apps and all this way, but what about malware? It seems we have very little guarantees about how clean these installs are, and yet I don’t see people worrying much about it. My neck hairs stand on end just thinking about it.
There is no way I know of to scan such a ready-to-run VMWare image for malware. There is no way to reliably scan them once they’re up and running, since they can easily be rootkitted or even contain malware compiled into the kernel.
Personally, I couldn’t dream up a better vector to get an entire package of malware onto sombebody else’s host or network than having them install an entire virtual machine preloaded with it.
But they sure are neat. I’ve downloaded one or two myself to test out preinstalled servers of different kinds, but I don’t think I’ll do that anymore.
More, but in Swedish
I’ve been a bit quiet lately, but that’s here only. I’m spending most of my writing energy on a new blog over here that allows me to relieve myself of a lot of the frustrations I have about the rotten state of medical software. I’m one of the site’s “official bloggers”, whatever that means. If you can read Swedish, and if you like seeing me suffer while having to use some good, some mediocre, and some really crappy software as I see patients, I’d love it if you’d visit that blog, too.
Complexity vs simplicity in software
We have a lot of vulnerabilities in software, and it doesn’t seem to diminish.
One of the major reasons we have all these vulnerabilities is that every software developer (or organization) needs to develop every darn litte thing itself. IOW, the networking code, the user interaction, the database handling, etc, just to be able to sell that one good idea or process that is their own. A very small part of every product is what differentiates it from the others, while the rest of the product is a rehash of what everyone does and has to do. Nobody likes to do all those parts, but we have to. And that’s where the vulnerabilities appear, in general.
Even though I don’t like the car analogy, I’m going to use it: it’s as if every car manufacturer had to create every high level system itself, like the braking system, electrical system, interior, etc. They don’t, they buy those from a few suppliers that know how to do that stuff right and cheap. The equivalence of APIs and operating systems would be components like wipers, bolts, nut, etc. The equivalence of the network stack would be the high voltage inductor, while the network handling code would be the ignition system.
Actually, it’s a bad analogy. One of the problems we have is that no physical analogy is right for software systems, so we keep misleading ourselves with them. But still, that’s my analogy for now.
We can’t quite yet get to the same level of component reuse in software as car manufacturers can. So every software engineer, in principle, has to create his own ignition system, even if he’s only interested in building his own idea of a sleek sports car. And, sure, his ignition system won’t equal one made by Bosch. Duh.
Trying to teach him how to make perfect ignition systems won’t work. He’ll be bored and distracted from his main interest. So this has to change.
(All the “software components” stuff is/was about this, but nobody has gotten the abstraction level right yet. They haven’t found the right place to cut the cables, so to speak. My feeling is they’ve always tried to solve too many problems in a too general way with all these systems, including Corba, COM, VCL, whathaveyou. Like I’d ever want to use a readymade ignition system in a juice press. Which actually may not even have a fuse box which the ignition system relies on. The analogy turns slightly ridiculous here…)
The other thing here is “complexity” vs “simplicity”. Complexity screws everything up. It causes exponentially increasing development times and bug counts. It makes for fragile systems and maintenance nightmares. But, you say, people want complex software… no they don’t. They want systems with complex behaviour, which is not the same as complex software. You can build very complex systems from a set of simple software units, if you do it right. That way the total complexity of the system increases linearly with size and function instead of exponentially.
This is what structured programming, OOP and all the rest is all about: trying to build complex systems using simple software. The trick is reducing complex processes to interacting simple processes, then treating each of them as a simple subsystem. Surprisingly few development organisations seem to get this and keep on building complex software using these techniques. Personally, I have a very hard time even imagining which system actually has to be built using complex software and can’t be done by a collection of simple software parts. I don’t really think there are any.
Dividing a complex system into simple software parts, if done right, makes each part easily manageable, allows you to divide the development organization into smaller coherent parts, allows easier documentation, easier testing and bug resolution, easier replacement, etc, etc. It’s a boatload of Good.
The current paradigm change (yey, got to use “the word”!) that’s occurring due to multi-cores will actually help. The transition will be very painful (developers and designers seem to have great difficulty thinking of business processes in anything but a sequential fashion), but if we’re lucky, that may be what’s needed. Pain is good.
Short version: you can’t confront “simplicity” with “complexity” without indicating what level of composition you’re talking about.
Amazing UI (1)
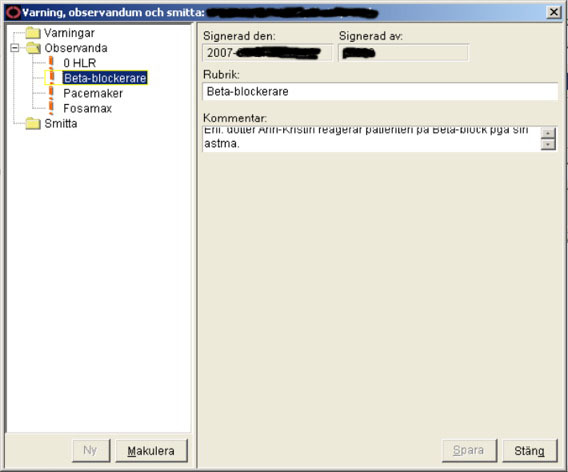
I figured I could start a series on “amazing UI” elements. Admittedly, practically all come from the multimillion electronic healthcare app I’m subjected to with frightening regularity. Just have a gander at this… note the expanse of grey to the right and the memo field with scroll bars squeezed into the upper part, with some illegible text in it. This is supposed to convey a description of an important warning about the patient. I usually try to be sanguine about it, but you really have to be retarded to design interfaces like this.
Cocoa, Core Data, and me (VII)
Time to figure out how to make a certain textfield gain focus. Remember, when doubleclicking the countries table, we want the drawer to slide open and the first field in that drawer to get keyboard focus automatically. We already got the drawer to open, so now is the time to get that focus thing working.
Cocoa, Core Data, and me (VI)
We’re still working to get the country browser right, and it isn’t right yet.
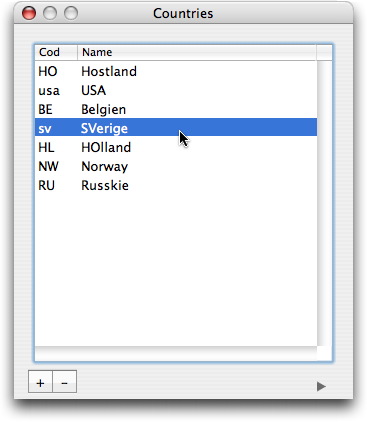
I don’t want the table in the browser to be editable, that is what the drawer is for. So when you doubleclick on a row in the browser, I want the drawer to slide out, if it’s not visible, and to have the focus set to the first field in the drawer. After editing is finished, I want the drawer to close again. If you click the “+” button, I also want the drawer to open so you can enter a new record. If you click the “-” button, I want the row to be deleted without any “Are you sure? Are you really sure? Are you really, really, really sure?” dialogs. After all, we have (or will have) full undo available.